I've got some dificulties in inserting bulk data using marqo.
WIth the docs being so inconsistent it doesn't really help so I'm back here again after trying for some time
My problem
I need to insert a lot of documents into the db so I wrote a java program that cuts them up into json format with the output looking like this:
[
{
"_id": "file.pdf",
"content": ["text1",
"text2"]
},
{
"_id": "file2.pdf",
"content": ["text1",
"text2"]
},
{
"_id": "file3.docx",
"content": ["text1",
"text2.",
"text3"]
}
]
This is valid json format, but when I look at example code on the site:
https://docs.marqo.ai/2.3.0/#searching-using-weights-in-queries
As you can see the multiline strings are not encased in a array, which in in itself isn’t that much of a problem to me but what does cause issues is when the other examples use json.load for extracting from a file.
This would then give an error about json syntax if I were to uphold the no array brackets.
Oh and this is what it looks like when you try to insert data into the db with array indication:
2024-03-21 17:45:12,798 logger:‘marqo’ INFO Errors detected in add documents call. Please examine the returned result object for more information.
And no I will not copy the simplewiki.json demo in it all being inside a single value, the whole reason I wrote a program in java was to not have to cut the documents up into parts in python, which simply took too long for me.
I simply ask for json syntax support to be added.
If I’m simply missing some info I would appreciate it if someone could point me to a solution.
Oh and is there by chance a way to dump all documents?
Like mq.index(“my-first-index”).get_documents(
document_ids=[“article_152”, “article_490”, “article_985”]
)
But instead of having to list the _id of every document a simple command would be appreciated aswell
output of results:
2024-03-21 18:13:41,778 logger:'marqo' INFO Errors detected in add documents call. Please examine the returned result object for more information.
{'errors': True, 'processingTimeMs': 0.5484679713845253, 'index_name': 'index001', 'items': [{'_id': 'Smartphone', 'error': "Field content '['A smartphone is a portable computer device that combines mobile telephone ', 'functions and computing functions into one unit.']' of type list is not of valid content.Lists cannot be tensor fields", 'status': 400, 'code': 'invalid_argument'}, {'_id': 'Telephone', 'error': "Field content '['A telephone is a telecommunications device that permits two or more users to', 'conduct a conversation when they are too far apart to be easily heard directly.']' of type list is not of valid content.Lists cannot be tensor fields", 'status': 400, 'code': 'invalid_argument'}, {'_id': 'Thylacine', 'error': "Field content '['The thylacine, also commonly known as the Tasmanian tiger or Tasmanian wolf, ', 'is an extinct carnivorous marsupial.', 'The last known of its species died in 1936.']' of type list is not of valid content.Lists cannot be tensor fields", 'status': 400, 'code': 'invalid_argument'}]}
Hi @DuckY-Y, as per the error you are receiving, arrays of strings cannot be tensorFields. Tensor fields must be strings. I think the confusion arises from the example in the docs using a specific behaviour in python for how string literals are parsed. String literals separated by whitespace in python are implicitly concatenated allowing for strings to be split on multiple lines. See the examples below
>>> print("This is a string " "which is continued")
This is a string which is continued
>>> print("this string"
... " is on two lines"
... )
this string is on two lines
Concatenating your strings in the arrays will resolve the error you are seeing.
Marqo will chunk your strings internally in line with the textPreprocessing settings for the index, if you need more granular control over text splitting then I would recommend splitting text into multiple documents and reconciling the results from search with your own logic.
As for dumping all docs in the DB, there isn’t a way to do this currently. We don’t have plans to support this at the moment as there isn’t a clear way to scale this for users with 10’s or 100’s of millions documents. The standard pattern we recommend is to track IDs externally to Marqo as typically data ingested into search systems comes from a separate single source of truth.
Lets me know if there is anything else we can help with.
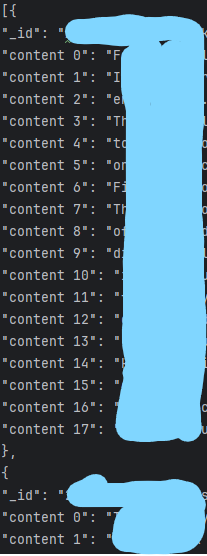
ah ok so one string one key,
My current script cuts up the documents into strings of 300 words with 5 word overlap.
Would you recommend I generate a “content N” before every string or to set the settings to 300 words? Would it impact the results in any noticeable way?
Something like this is what I mean.
Example key usage
I get my attempt would be hard to make practical with my other wishes like
tensor_fields=["content"]
I take it there is no such option as
tensor_fields=["content %"]
Or maybe a blacklist instead of whitelist
Oh and it appears that
[
{
"_id": "01",
"content_1": "A smartphone is a portable computer device that combines mobile telephone ",
"content_2": "functions and computing functions into one unit."
},
{
"_id": "02",
"content_1": "A telephone is a telecommunications device that permits two or more users to",
"content_2": "conduct a conversation when they are too far apart to be easily heard directly."
},
{
"_id": "03",
"content_1": "The thylacine, also commonly known as the Tasmanian tiger or Tasmanian wolf, ",
"content_2": "is an extinct carnivorous marsupial.",
"content_3": "The last known of its species died in 1936."
}
]
With
with open('test.json', 'r', encoding='utf-8') as file:
documents = json.load(file)
output = mq.index("index001").add_documents(documents, tensor_fields=["content 1", "content 2", "content 3"])
So I guess it does make sense not to limit the tensor fields to be constant throughout the whole index. thx for that
1 Like
Yep, you can have a different schema with different tensor fields for each document. The same applies for multimodal combination fields where you can have different combinations of images and text for each document as well.